
「スクレイピングを使って作業を自動化させたい」
本記事はそんな方に向けられた書かれています。
pythonを勉強していると、「スクレイピング」というものを知ることもあるでしょう。
スクレイピングの内容について知って、「自分もやってみたい!」と思った方も多いのではないでしょうか?
スクレイピングができるようになると、普段の仕事の業務も効率化できるようになるかもしれません。
プログラマーとしてやれることが広がり、あなたのスキルが一段階アップするような感じになります。
とはいえ、いきなり本格的なスクレイピングをやろうとすると躓く人は多いでしょう。
本記事ではスクレイピングの「最も基本的なやり方」についてご紹介していきます。
python学んでからまだ1週間ぐらいしか経っていない人でも分かるように説明していきますので、ご安心ください。
目次
スクレイピングとは?
スクレイピングとは、webページの情報を取得することです。
PythonではWebページにアクセスすればことによって、Webページの中身を取得することができます。
Webページの中身を取得し、そのデータを分析することによって、様々なことができるようになります。
例えば本日の天気を記録したWebサイトを取得することで、毎日の天気の情報を纏められるようになります。
webページを手動で取得しようとすると、webページにアクセスしてコピーアンドペーストを繰り返すことになり、とてもめんどくさいです。
しかしPythonで自動化してしまえば、一瞬でwebページの情報を取得できます。
取得したwebページの情報は、見やすいように整えた後にエクセルに表示したりして、始めて実用化できます。
ただし、初心者でそこまでするのは難しいです。
本記事ではひとまず、webページの内容を何も変えず丸ごと取得して、ファイルに保存する所まで解説します。
Pythonでwebページをスクレイピングする方法を学ぶ
それでは、pythonでwebページを取得する方法を学んでいきましょう。
本記事に書かれた通りに行えば、誰でも簡単にスクレイピングできます。
requestsモジュールをインストールしてインポートできるようにする
まずはrequestsモジュールをインストールしましょう。
Webサイトの情報を取得する際には、requestsモジュールが必要です。
モジュールとは「ある機能を実現するためのプログラムの纏まり」のことで、requestsモジュールはwebサイトを取得するためのプログラムが纏まっています。
モジュールを使えるようにするためには、お使いのパソコンにインストールする必要があります。
requestsモジュールをインストールするには、コマンドプロンプトから以下のコマンドを打つ必要があります。
pip3 install requests
インストールに成功したら、ソースコードの1番上に以下のように記述しましょう。
import requests
「import モジュール名」と書くことで指定したモジュールをコード内で利用できるようになります。
これでrequestsモジュールが使えるようになりました。
Webページのデータを取得
次にPythonでwebページのデータを取得します。
Webページにアクセスするには、GETメソッドを使います。
GETメソッドを使うことで、サーバーからのレスポンスを受け取れるようになります。
ここでは「プログラミングスクール比較サイト」のトップページのデータを取得してみます。
import requests
requests.get('https://websites-manual.com/')
requests.get({URL})と記述することで、指定したURLのデータが取得できるようになります。
たったこれだけのコードでwebページのデータは取得できるのです。
後は取得したデータを取り出して保存するだけです。
getメソッドの戻り値からwebページのデータのみを取り出す
getメソッドを使って、データは取得できましたが、これをこのまま表示してもwebページの情報は表示されません。
import requests
data = requests.get('https://websites-manual.com/')
print(data)
上記のコードを実行すると以下のように出力されます。
![]()
この「200」という数字は、サイトのステータスコードです。
getメソッドはそのまま出力するとステータスコードを返すだけで、情報は返しません。
requestsオブジェクトの中からテキスト属性だけを抽出する必要があります。
そのためには「.text」とつける必要があります。
import requests
data = requests.get('https://websites-manual.com/')
print(data.text)
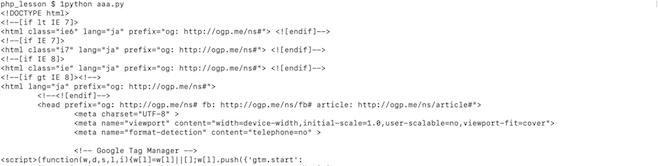
こうすることでrequestsオブジェクトの中のテキスト属性だけが表示されます。
これでwebページの情報が出力されるようになりました。
htmlファイルに保存する
後は取得したデータをファイルに保存するだけです。
書き込む用のhtmlファイルにアクセスするには「open」というメソッドを使います。
そしてファイルに保存するには、「write」というメソッドを使います。
import requests
data = requests.get('https://websites-manual.com/')
print(data.text)
with open('website.html', 'w') as file:
file.write(res.text)
これで、webページのデータが丸ごとファイルに保存されるようになりました。
保存したhtmlファイルをダブルクリックして見て下さい。
(ファイルはソースコードが置いてあるフォルダと同じ場所に保存されます)
立ち上がったブラウザに、「プログラミングスクール比較サイト」のトップがそのまま表示されると思います。
以上が、基本的なスクレイピングのやり方となります。
まとめ
本記事ではスクレイピングの基本的なやり方について説明しました。
本記事で書いたことはあくまでスクレイピングの初歩的なやり方に過ぎず、とても実用的ではありません。
後はhtmlタグを削除したり、データをエクセルに書き込んだりする処理を学んでいけば、高度なスクレイピングができるようになっていくでしょう。
ぜひこれからどんどんPythonを勉強していって、自由自在にスクレイピングができるプログラマーになってくださいね。


